Are Local LLMs the solution to all our problems?

It feels like there is a growing gap between people who are deep in technology/AI space (like myself) and everyone else about whether AI is good or bad. Take, for example, this study [1] done in the US on whether people think AI will have a positive or negative effect on the US over the next 20 years.
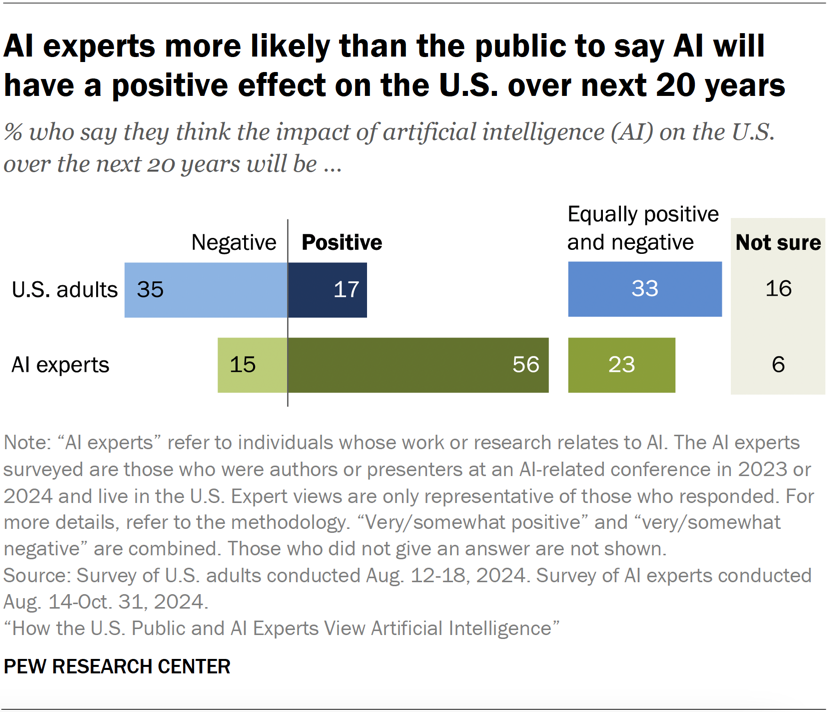
[1]
The difference here is quite staggering, and is certainly not the vibe you get in tech-focused spaces. It seems like every tech company is integrating AI into their products as if their lives depend on it, and Nvidia stock seems to be infinitely growing in value. Specifically in the developer space (where I live) it feels like everyone is using AI to speed up their development workflow and are producing apps faster than they can think of catchy domain names to deploy them to!
Whereas, in my personal life, most people I talk to really don’t like AI. When companies signal their move toward using more AI, there is sometimes quite a strong backlash from the public. For example, the social media backlash around Duolingo[2]. There are a few main concerns that the general public have about AI: its impact on the environment, copyright concerns around training data, privacy concerns, and the threat of replacing human workers. To focus primarily on the environmental impact: AI models, more specifically Large Language Models (LLMs) take a whole lot of computing power to train and also to run day-to-day. This has driven large increases in demand for data centers and, as a result, electricity. Well, what if we didn’t need all that data center grunt, can we just run LLMs on our existing hardware? Turns out we can! Enter open-weight LLMs. Open-weight LLMs are effectively open source (they’re technically not actually open source which is why we call them open-weight) LLMs that you can download and run on whatever hardware you like, including your laptop! So, one can imagine a world where instead of getting ‘bleeding-edge’ performance from the very best models running in the cloud, we can get ‘good enough’ performance at the cost of your laptop battery draining a bit faster. Is such a world possible today?
Note: Literally the day that I am writing this article, OpenAI has just released its first-ever set of open-weight models. They look very promising and would potentially have changed the conclusions I made here.
In my best attempt to answer this question, I got a set up working really quickly using LM Studio and Aider. On my 2021 M1 Pro Macbook Pro (with 32GB of RAM), the best models I have found for my use case are qwen2.5-coder-14b and qwen3-30b-a3b which use ~8GB and an eye-watering 18GB of RAM, respectively. While I did get slightly better results with the larger model (it even seemed to work faster, due to whatever magic allows it to only have 3B active parameters), the more-than-doubling of RAM usage was unacceptable. The results I was able to get out of qwen2.5-coder-14b were pretty good. It's able to refactor bloated types for me, as well as fix tests that are failing due to missing React contexts. Though, it is immediately obvious that it is running on my laptop and not some GPU compute cluster somewhere in the cloud, when the first token takes around 15-20 seconds to appear. The code it generates does sometimes need some tweaking, though the process is certainly faster than having to read documentation to refresh my memory on seldom-used syntax. Now, looked at in isolation, these results are pretty good. I can effectively work on multiple issues at the same time, firing off a prompt about a simple-looking bug that’s cropped up. Then, while I wait for the LLM to get back to me, I can go and fix another one that requires a bit more contextual knowledge. By the time I'm done, there should be a maybe 80-90% ready solution for the bug that I can quickly tweak and commit right after.
Well, they say 'Comparison is the thief of joy', and here it is: Github Copilot. State-of-the-art models, running on whatever hardware necessary. How many gigabytes of RAM it takes to run is not my problem. And all for just $10USD/Mo. And with great computing power comes some pretty great results: Using the same prompt as I did for my local model, I got it to try and fix the same test that was failing (from the missing context). To solve my problem, Copilot generated a first draft of a mock context. It then realised that this mock was throwing a type error. So it searched the codebase for the type definition, figured out what properties it was missing, and added them. Now that it knew it had correctly-compiling code, it asked if it could run the failing test, which passed, it then knew to run the entire test suite to ensure it hadn't broken anything anywhere else. And it did all the above in the time the local model took to just generate its best guess at a fix. A lot of the gains here come from the tool calls that Copliot does, and I know that I theoretically could get a similar setup with the Qwen model running locally. But as far as I understand, that requires a whole lot of manual setup, and Qwen2.5-coder was not trained for tool calls.
Let’s loop back to why we’re looking at locally-running LLMs in the first place: energy usage. Estimating energy usage for AI, especially for something like Copilot, is difficult for many reasons. 1. We don't know how big models like Sonnet 4 and GPT 4.1 actually are. 2. LLMs for this use-case have very large context windows and are doing specialised tool-calls, and I can only guess that this has a higher electricity cost than your typical ChatGPT request. 3. Even if the first two things are known, LLM electricity usage is hard to quantify anyway, even small variations in more 'standard' prompting can make the LLM work much harder. All that being said, here is a very rough estimate: An article from MIT Technology Review[3] estimates that Llama 3.1 (405B parameters) uses 6706 joules, on average, per response. For reference, it is estimated that GPT-4 could have over 1T parameters. So lets say that the average prompt for Copilot running GPT 4.1 is 5 times more expensive than that, 33,530 joules. Lets say that our 7 Abletech devs are doing 30 prompts a day, 5 days a week: 33530 * 7 * 30 * 5 = 35,206,500 joules/week, which converts to roughly 9.78 kWh/week. For reference, the maybe 10-year-old fridge that came with my apartment is rated to use 10.58 kWh/week. I think the question around water usage falls into a similar category as electricity usage. Yes, generative AI is a GPU-intensive task, and GPUs run hotter than CPUs, so it does create a higher demand for cool water. But as shown by the above estimations, the extra demand that we, as an organisation, create is but a drop in the pond. That’s just the energy required to run the model on an ongoing basis. The other component of this is the energy used to train these models. This is massive, an MIT News article[4] states that for GPT-3 (from 2020) 'the training process alone consumed 1,287 megawatt hours of electricity (enough to power about 120 average U.S. homes for a year)'. I am sure that something like GPT4.1 or Sonnet4 used significantly more than that. And, to circle back to my point, the local LLM models will have consumed similar amounts of energy to be trained, so by using them we're not really 'saving' on that front.
To briefly address the ethical concerns around training data. Unfortunately, local/open-source LLMs are trained on just-as-sketchy data. Meta's open-weight LLaMa 3 was trained on Books3 which contains hundreds of thousands of pirated books and was also the subject of a lawsuit from many of the authors of said books[5].
This wraps around to the more general question: How much impact can one small organisation even have here? It is unquestionable that the general trend of AI and the industry-at-large has significant effects on the environment. Quoting again from MIT Technology Review[3]: 'AI-specific servers [...] are estimated to have used between 53 and 76 terawatt-hours of electricity. On the high end, this is enough to power more than 7.2 million US homes for a year.'. And the ethical questions around training data are unavoidable if you are using generative AI in any capacity. So, will moving our handful of devs off of Github Copilot and onto some combination of Qwen models and Aider have a measurable impact on the environmental effects of AI-at-large? No. Will it even have a significant impact on the carbon footprint of our Organisation? Not really. But is taking a step in the 'right direction' here worth the trade-offs? With the current state of the technology, and in this particular context I would lean towards no. Though in just 12 months this whole thing might flip on its head. We might be able to run models with big contexts and tool-usage baked in directly off of our laptops, merely sipping at the RAM and GPU. At which point this question will be worth revisiting.
You may have noticed that completely dodged talking about privacy and replacing human workers. I am not even close to being qualified to talk about the latter, so I will leave that one alone. However, I do plan on doing a follow-up article about privacy and that will likely be through the lens of a more general user compared to a developer. That might be a situation where the local model is 'good enough' and the other contributing factors outweigh the performance left on the table. Stay tuned!
Sources
[1] pewresearch.org
[2] wired.com
[3] technologyreview.com
[4] news.mit.edu
[5] theatlantic.com